
UxSID: Semantic-Aware User Interests Modeling for Ultra-Long Sequence
UxSID: Semantic-Aware User Interests Modeling for Ultra-Long Sequence
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | UxSID: Semantic-Aware User Interests Modeling for Ultra-Long Sequence |
| 作者 | Hongwei Zhang, Qiqiang Zhong, Jiangxia Cao, Yiyang Lv, Huanjie Wang, Liwei Guan, Jing Yao, Junfeng Shu, Yiyu Wang, Zhaojie Liu, Han Li |
| 机构 | Kuaishou Technology(快手) |
| 年份 | 2026 (arXiv 预印, 5 月) |
| 方向 | Ultra-Long Sequence Modeling, Semantic ID, Target-Aware Attention, 离线预计算 |
| 场景 | 工业级广告推荐,超长用户行为序列(10k 级)建模 |
| arXiv | https://arxiv.org/abs/2605.09040 |
TL;DR:超长序列建模长期集中在"逐候选检索 SIM/TWIN"和"与目标无关的压缩 MIMN/C-Former"两条路线上。UxSID 主张走中间路线: 不为每个 item 单独压缩,计算代价过高;也不做完全 target-agnostic 的压缩,会丢失目标相关的兴趣峰值;而是按 Semantic ID 语义组来共享一份压缩好的用户兴趣记忆,语义相近的 item 共用同一份。这样既能离线预计算、线上 查表,又保留了"目标语义感知"。
关键方法:用目标 item 的 SID 当 query 去 attend 用户历史,离线把
(UID, SID)这一对的兴趣 embedding 算好存进 KV,线上拿到候选只需Hash(UID ⊕ SID)查一次表,复杂度与序列长度无关。
一、动机与背景
超长序列建模的核心矛盾:效率 vs 效果
用户行为序列越长,越能刻画长期兴趣,近年来是公认的提升方向。但推荐系统流量规模很大,序列长度一旦增加,在线计算量显著增加: 这是一个难以回避的 trade-off。如何在"输入更长的序列"和"保持线上轻量"之间取平衡,现有工作大致分两条技术路线:

路线一:Search-based Top-K 选择,即 item-specific 的逐候选检索。 代表是 SIM、ETA、TWIN、SDIM。核心做法:不直接处理超长序列,而是用一个 General Search Unit GSU 针对每个候选 item 从长序列里检索出一个 item-specific 子序列,例如与候选同类目或相似的历史行为,再把短子序列输入后面的精排注意力。
- 问题 1:选择偏差。检索这一步受限于预定义的 key 空间,例如按类目或作者 ID 匹配,表达力有限,固定的检索范围会遗漏那些表面相关性低、但语义上确实相关的远端行为,即 hidden semantic synergy。
- 问题 2:逐候选检索本身存在成本,且 GSU 的硬筛 quota 也是一个超参。
代表工作:
- SIM(Alibaba,CIKM 2020):两级检索的奠基工作。GSU 从超长序列(最长达 5.4 万)按类目硬检索或向量内积软检索出与候选相关的子序列,ESU 再对该子序列做精确 target attention。
- ETA(Alibaba,arXiv 2021):用 SimHash / LSH 把向量内积近似为汉明距离计算,使 GSU 检索可端到端训练,免去 SIM 中需离线异步维护检索索引的工程代价。
- TWIN(Kuaishou,KDD 2023):让 GSU 与 ESU 采用一致的 target-attention 相关性度量,消除两级度量不一致导致的「GSU 漏掉真正相关行为、却检索到无关行为」问题。
- SDIM(Meituan,CIKM 2022):用多个哈希函数为候选与各历史行为生成签名,直接聚合与候选同签名的行为得到兴趣表示,复杂度随序列线性增长、对线上 CTR 服务近似零延迟。
路线二:Pre-trained 用户兴趣压缩,即 item-agnostic、与目标无关的压缩。 代表是 MIMN、LURM、C-Former、PinnerFormer。核心做法:把超长序列离线压成少量与目标无关的用户兴趣记忆 dense memory,线上模型直接读这份高度压缩的记忆来感知长期兴趣。
- 问题:压缩是 target-agnostic 的: 它不知道当前要打分的候选是什么。静态压缩相当于一个低通滤波器,保留了粗粒度的全局趋势,却把"针对当前目标的高频兴趣峰值"平滑掉了,还会在融合多样兴趣时引入无关噪声。
代表工作:
- MIMN(Alibaba,KDD 2019):用 NTM 记忆网络加 MIU(Memory Induction Unit),配合独立的 UIC(User Interest Center)增量地把终身行为压入固定大小的记忆槽,将最耗资源的兴趣建模与在线打分解耦、对实时 CTR 零延迟。
- LURM(蚂蚁集团 Ant Group,2021;同脉络见 KDD’23 arXiv 2110.11337):自监督学习通用用户表示。BoI(Bag of Interests)把任意时段行为编码成超高维稀疏向量,SMEN 经对比学习映射成多个低维用户表示;表示与目标无关。
- C-Former(Kuaishou,CIKM 2025):以「终身行为聚类」作为压缩手段,用 transformer 将行为聚成固定数量的簇,使检索可在簇上进行,从而触达终身行为又保持推理效率。
- PinnerFormer(Pinterest,KDD 2022):离线(按天)用 transformer 配合 dense all-action 预测损失,把用户序列压成单条用户 embedding 供下游检索;表示离线生成、与目标无关。
感觉这里其实路线划分不严谨,这篇文章本身是 2026 年的文章,序列统一建模这个时候已经涌现出如 OneTrans、TokenMixer、HyFormer 等一系列工作了,也都是在长序列基础上做的,这些方法没有做候选检索或者静态压缩,而是靠高效注意力、kvcache、精度混合等方法实现的。
UxSID 的主张:语义组共享
作者的论点是:上面两条路是两个极端: 要么完全 item-specific、每个 item 一份,要么完全 item-agnostic、全用户一份。中间还有一条尚未被充分探索的路线:保留用户序列与目标 item 的"部分相关性",仅暴露有限的信号来引导压缩的方向。 不追求 per-item 的压缩,而是按 item 属性寻求语义组共享的通用兴趣记忆: 语义相近的 item 共用同一份压缩后的用户兴趣记忆。
这个"有限信号"就是 Semantic ID,简称 SID。SID 是把 item 的多模态属性,包括文本、图像等 metadata,经 RQ-VAE 这类深度量化得到的离散语义簇编码,天然对齐"用户兴趣簇"。用 SID 当压缩的 condition,就能在粒度过细的逐物品和粒度过粗的无关压缩之间,取一个按语义分组的中间粒度。
论文 Fig 1 概括了三种范式:Item-specific Search 为每个候选在线筛序列,计算代价高;Item-agnostic Compression 离线蒸馏成静态记忆,但 target 无关;UxSID 走语义组路线,SID 相同的 item 共享一份压缩兴趣记忆。
创新点
- Target Semantic-Aware Behavior Compression:作者称这是第一个把"SID 携带的目标语义"接入超长序列建模 ULSM 的工作: 用 SID 当 query 去探询用户历史,而不是做 user-centric 的静态蒸馏。
- 可扩展的 UxSID 架构:两阶段框架,包含 Item-Agnostic 兴趣压缩与层次化目标注意力,保证即便在 10k 交互下仍是常数时间推理。
- SOTA + 工业落地:公开 benchmark 达到 SOTA,快手广告线上 +0.337% revenue。
二、问题形式化
Semantic ID 的定义
给定一个 item 的多模态属性,先用多模态大模型编码成稠密向量:
其中 为第 个 item 的多模态属性,包括文本、图像、世界知识, 为多模态大模型编码器, 为编码得到的稠密语义向量,下标 标识 item。
再做层次化残差量化,如 RQ-VAE、Res-Kmeans-FSQ 之类,得到 层离散码:
其中 为残差量化的总层数, 是第 层 codebook, 为该层第 个码向量, 是该层量化残差, 为进入第 层量化的输入残差, 为第 层 codebook 中第 个码向量, 为该层取到的最近码的下标,下标 遍历该层 codebook 的所有码。实现中取 层、每层 codebook 大小 256,即 。最终一个 item 的 SID 形如 <7>,<5>,<9>,...,语义相近的 item 会落到相同或相近的 SID: 这是后面"语义组共享"的基础。
目标
记用户原始行为序列 ,其中 可达 10k,其 embedding 序列 。UxSID 要产出一个目标语义感知的压缩表示 ,要求:
- 计算节俭:线上代价与序列长度 无关;
- 目标语义感知:表示随目标 item 的 SID 而变;
- 离线-在线一致,即 online-offline parity:线上读取的,就是离线算好的。
三、方法 / 模型架构
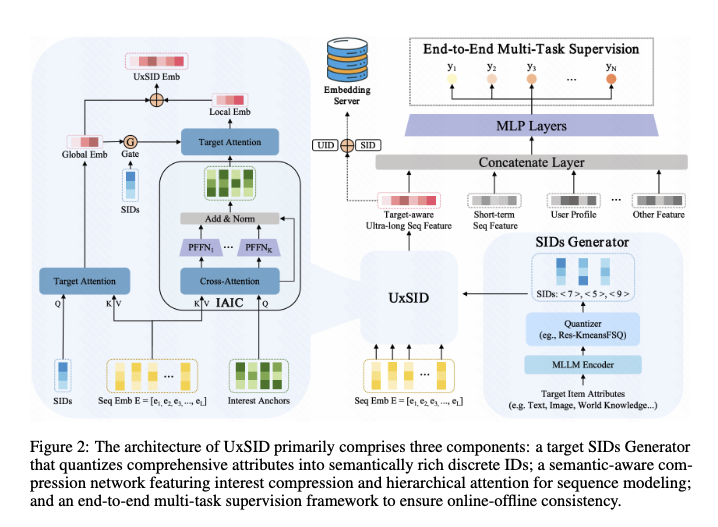
整体分为三个部分:
- Target SIDs Generator:把 item 属性量化成离散 SID。
- Semantic-Aware Compression Network: 含兴趣压缩 IAIC 与层次化双层注意力。
- End-to-End Multi-Task Supervision Framework: 多任务监督学习。
3.1 SIDs Generator
编码器:把 item 的 metadata 经一个 MLLM encoder 编成稠密向量 (即 §二 那一步)。
量化器:不是纯 RQ-VAE,而是论文自述的 Res-KmeansFSQ 混合量化: 残差量化叠加 K-means 与 FSQ(Finite Scalar Quantization)。形式化地,记初始残差 ,第 层在码本 中取与当前残差最近的码、再将其从残差中减去传入下一层, 层后累加重构:
codebook 与 SID 结构:各层码拼成该 item 的 SID:
公开实验为 层、每层 码。工业部署做了关键简化:线上主要只用第一层码 作为 target SID(即 ),并把第一层 codebook 放大到 。
query 构造: 具体如何由码得到,论文未明确;结合工业部署只用 ,最可能是按 查一张可学习的 SID embedding 表:
第一层码相同的 item 构成一组:
3.2 Item-Agnostic Interest Compression
这一阶段先不引入目标,把原始长序列 压成 个兴趣锚点 ,其中 ,实现取 。
(1) Cross-Attention 压缩:用 个可学习的兴趣锚点 当 query,长序列当 key/value:
其中 分别为 query、key、value 的投影矩阵, 为 embedding 维度, 为缩放因子, 为压缩后的 个锚点表示。
这一步把长度为 的序列压到固定 个 slot, 这是后面"常数时间"的来源。
(2) Per-token FFN,记 PFFN:每个锚点 过一套自己专属的 FFN,参数 按锚点独立,再残差 + LayerNorm:
其中 为第 个锚点的输入表示, 与 为第 个锚点专属的两层 FFN 权重与偏置, 为非线性激活函数, 为该锚点经残差与 LayerNorm 后的输出表示,上标 表示参数按锚点独立。
这与 MPFormer 的 per-task MLP 思路一致: 让每个锚点使用独立参数,避免不同兴趣面被同一套变换混合到一起。
(3) 正交与多样性约束:为了让 个锚点各自对应一个兴趣面、避免塌缩成同一个,加一个正交正则,逼近"锚点两两正交":
其中 为 个兴趣锚点堆叠成的矩阵, 为其归一化所用的谱范数,即最大特征值, 为 单位矩阵, 为 Frobenius 范数, 为正交正则项。
这一 正交正则最早见于 Lin et al., ICLR 2017,用惩罚项 让多个 attention 向量各关注一处、去除冗余;UxSID 这里是其归一化变体。推荐侧自 MIND(胶囊路由)、ComiRec(自注意力)起,多兴趣向量易塌缩成同一个,正交 / disagreement 正则便成了常见解法。
3.3 Hierarchical Semantic Probing 双层目标注意力
得到与目标无关的锚点 后,再引入目标 SID ,分两级做 target-aware 的探询。注意两级 attend 的对象不同: 一个 attend 原始全序列以获取细粒度全局信号,一个 attend 压缩锚点以获取去噪后的局部意图。
Stage 1 — Explicit Semantic Probing,全局,attend 原始序列:
其中 为目标 SID 聚合得到的语义 query 向量, 为全局注意力的 query、key、value 投影矩阵,下标 表示全局阶段, 为对原始全序列做目标注意力得到的全局兴趣表示。
直接对原始全序列做目标注意力,恢复细粒度、target-specific 的信号,也就是压缩可能滤掉的那部分"高频峰值"。这里有一个隐含的代价:attend 原始序列 的复杂度是 。论文之所以能做到常数时间,是因为这部分离线计算。线上只查表,不在线运行这个 。
Stage 2 — Gated Latent Probing,局部,attend 锚点:先用全局信号算一个上下文门控向量,去 refine query,再 attend 压缩锚点 :
其中 为以全局信号为输入的门控网络, 为激活函数将输出压到门控取值范围, 为上下文门控向量, 为逐元素相乘, 为经门控调制后用于局部注意力的精炼 query。
其中 为局部注意力的 query、key、value 投影矩阵,下标 表示局部阶段, 为前一阶段得到的压缩兴趣锚点, 为对锚点做目标注意力得到的局部兴趣表示。
门控 让全局信号调制目标 query: 先由全局信号确定大方向,再带着这个方向在压缩锚点中精确定位局部意图。Gate 在消融实验中有效,去掉后指标下降。
最终表示:两级拼接,而非相加:
3.4 端到端多任务监督
与其它特征拼接后输入精排 MLP,做 CTR、CTCVR 多任务预测:
其中 为一条样本, 为该样本的预测点击或转化概率, 为 sigmoid 函数把 MLP 输出映射到 , 目标 item 特征、 用户画像、 上下文、 短期序列特征。总损失 = 交叉熵 + 正交正则:
其中 为样本数,下标 标识第 条样本, 为其真实标签, 为对应预测概率, 为正交正则项的权重系数。
注意:
- 离线预计算的超长序列 UxSID 与线上实时的短期序列 是两条独立的输入。这回答了"预计算的 embedding 是否会过时"这一问题: 长期兴趣变化缓慢,离线计算、容忍一定 staleness 是可接受的;而对时效敏感的近期行为,交给线上短期模块实时计算。两者职责分离明确。
- 长序列 多兴趣锚点 CrossAttention 和 SID 两阶段 Cross Attention 的计算过程均发生在离线,这部分最终的产出仅仅为 。也就是长序列依靠 SID 和 多兴趣锚点融合最终压缩成了一个 Embedding。
3.5 在线服务与离线-在线一致性
整个双层注意力,含 的全局 attend,都在离线完成。对每个 (用户 UID, 目标 SID) 对,离线算出 ,按下式存入分布式 KV,即 Embedding Server:
其中 为用户标识, 为目标 item 的 Semantic ID, 为二者的拼接或组合算子, 为哈希函数, 为 KV 表的查询键, 为离线预计算并存入的兴趣表示。
线上到达一个候选 item:取它的 SID → 算 Hash(UID ⊕ SID) → 一次哈希点查取得预计算好的 embedding,,与 无关。
"语义组共享"在这里实现:因为 SID 相同的 item 共用同一份用户兴趣记忆,需要存储的不是十亿级的"每用户 × 每 item",而是"每用户 × 每 SID 组"。实测平均每用户约 100 个 SID,400M 用户总共约 2.56 TB,现代分布式 KV 可以承载。反推存储量可验证自洽:64 维 embedding × 约 100 SID × 400M 用户,若按 int8、1 字节每维,约 B = 2.56 TB,数值吻合,说明 value 是量化存储的。
为什么强调 online-offline parity? 因为线上读取的就是离线训练时算出的那一份 embedding,逐比特一致,不存在线上另行运行一套近似编码器、导致 train/serve skew 的问题: 这恰恰是部分压缩类方法的隐患。线上额外延迟仅 +0.16 ms。
四、为什么这条"中间路线"成立
本质是一个压缩粒度的可调参数:
| 粒度 | 代表 | 存储/计算 | 目标感知 |
|---|---|---|---|
| 最细:每 item 一份 | SIM / TWIN(逐候选检索) | 线上逐候选计算,代价高 | 强(item-specific) |
| 中间:每 SID 组一份 | UxSID | 离线预计算,线上 查表,约 100/用户 | 中(语义组级) |
| 最粗:每用户一份 | MIMN / C-Former | ,开销最低 | 无(target-agnostic) |
两个极端各有明显短板:item-specific 计算代价高且受 GSU key 空间偏差影响;item-agnostic 开销低但类似低通滤波器、把目标相关的兴趣峰值平滑掉了。SID 组数就是这个可调参数: 它远小于 item 数,因此预计算加查表可行,又远大于 1,因此保留了目标语义区分度。SID 在这里充当"暴露给压缩的有限信号",恰好把压缩方向引导正确。
复杂度对比, batch、 原始序列长、 检索子序列长、 隐层、 压缩兴趣数、 为 TWIN 中目标无关行为打分所用的特征数:
| 模型 | 推理复杂度 |
|---|---|
| DIN | , |
| SIM-Soft | |
| TWIN | |
| C-Former | |
| UxSID | , |
UxSID 线上复杂度只与固定的 有关,与 解耦: 这是"序列扩展到 10k 也不增加线上成本"的根本原因,主要计算全部在离线。
五、实验
5.1 数据与指标
| 数据集 | 用户 | item | 交互 | 平均序列长 |
|---|---|---|---|---|
| XLong | 1,000 | 3,269,017 | 1,000,000 | 1,000 |
| KuaiRec-Big | 7,176 | 10,728 | 12,530,806 | 1,746 |
| 工业数据集(快手广告) | — | — | impression logs | 最长 10k |
指标:AUC、UAUC / WUAUC,即用户级与加权用户级、Interest Recall@K,记 Int.R@K,衡量兴趣路由质量。Baseline 覆盖两条路线:search-based 的 DIN、SIM-Hard/Soft、ETA、SDIM、MIRRN、TWIN,以及 compression-based 的 C-Former。
5.2 主结果
公开数据集,Table 1,AUC,最优加粗:
| 模型 | XLong | KuaiRec-Big |
|---|---|---|
| DIN | 0.7889 | 0.8181 |
| SIM-Soft | 0.7971 | 0.8279 |
| TWIN | 0.8154 | 0.8269 |
| C-Former | 0.8135 | 0.8276 |
| UxSID | 0.8408 | 0.8348 |
工业数据集,Table 2,AUC:
| 模型 | CTR | CTCVR |
|---|---|---|
| SIM-Soft | 0.8711 | 0.8608 |
| TWIN | 0.8712 | 0.8609 |
| UxSID | 0.8728 | 0.8626 |
公开集上 UxSID 相对 TWIN、C-Former 领先明显,XLong 0.8408 对 0.8154、0.8135,约 +2.5 pt;但工业集上相对 TWIN 的领先收窄到 CTR +0.0016、CTCVR +0.0017。工业 AUC 本身提升难度较大,这种量级的提升在整体流量上仍可能带来可观收益,下面的 A/B 验证了这一点。
5.3 消融实验
| 变体 | XLong AUC | 结论 |
|---|---|---|
| 满配 UxSID | 0.8408 | — |
| w/o | 0.8370 | 掉最多,细粒度全局信号关键 |
| w/o | 0.8375 | 压缩锚点也重要 |
| w/o Gate | 0.8376 | 门控调制有效 |
| w/o | 0.8385 | 正交约束有正贡献 |
| 用类目/Tag 当 query 代替 SID | Int.R@50: 0.0543 vs 0.1488 | 用 SID 路由兴趣显著优于 Tag |
去掉全局比去掉局部的指标下降更多,0.8370 低于 0.8375,说明**"直接 attend 原始全序列恢复的细粒度信号"是主要贡献**: 这也反过来支撑了作者对 item-agnostic 压缩"低通滤波丢失峰值"的批评。SID 与 Tag 的对比是一组关键证据:把 query 从 SID 换成人工类目,Int.R@50 从 0.1488 显著下降到 0.0543,约为原来的 1/3。这证明性能提升不是来自多向量压缩本身,而是 SID 携带的语义确实在做有效的兴趣路由。
5.4 序列长度扩展
随序列长度增长到 10k,UxSID 始终保持最高 AUC,且在 10k 处与 SIM、TWIN、C-Former 的差距进一步扩大,论文只给出曲线、未给 10k 精确数值。
5.5 线上 A/B:Table 3,快手广告,一周
| 指标 | 提升 |
|---|---|
| Exposure(曝光) | +0.111% |
| Cost(消耗) | +0.231% |
| Revenue(收入) | +0.337% |
曝光 +0.111% 而收入 +0.337%,收入增幅大于曝光增幅,说明收益主要来自转化精度提升,即更精准地把广告投放给会转化的用户,而非单纯增加曝光量: 与工业集上 CTCVR 同步提升的方向一致。
5.6 工程开销
- 存储:约 2.56 TB,对应 400M 用户、每用户约 100 SID,分布式 KV 可承载。
- 线上延迟:+0.16 ms。
- 训练:1k 序列用 16 张 A10;10k 序列用 40 张 A10。
- 超参:锚点数 , 欠拟合、过大引入冗余;;SID 层 codebook 各 256; 需调优,过大会过度约束锚点。
六、讨论
6.1 缺少与其它统一序列建模工作的对比
论文没提 OneTrans、Hyformer、TokenMixer 等同期或者稍早一些的 统一长序列建模的工作,这些没有做压缩的办法感觉应该要对比一下才是。
6.2
七、总结
UxSID 的核心贡献不是某个新算子,而是把超长序列建模的设计空间显式参数化为"压缩粒度",并指出 SID 语义组是此前被忽略的折中点:
- 比 item-specific 检索成本更低:离线预计算、线上 查表,与 解耦;
- 比 item-agnostic 压缩更精细:按 SID 分组,保留目标语义区分度,不退化为低通滤波器;
- 工程上 online-offline 逐比特一致、+0.16 ms、2.56 TB 可落地,快手广告 +0.337% revenue。








