
DSIN: Deep Session Interest Network for Click
DSIN: Deep Session Interest Network for Click
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | Deep Session Interest Network for Click-Through Rate Prediction |
| 作者 | Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, Keping Yang |
| 机构 | Alibaba Group |
| 年份 | 2019 (IJCAI’19) |
| 方向 | Session Interest, Self-Attention, Bi-LSTM, Sequential Modeling |
| 场景 | 电商展示广告 session 级用户行为序列建模 |
| arXiv | https://arxiv.org/abs/1905.06482 |
DSIN是继DIEN改进DIN之后,进一步改进DIEN的工作,作者不再是G Zhou,论文的实验也不再包含工程上的效果评估,没有提及是否上线有涨点,似乎相较于DIN和DIEN来说更学术风一些。
作者blog:https://yufeifeng.github.io/
作者知乎:https://www.zhihu.com/people/fengpang
背景/动机/创新点
作者认为用户行为序列存在特征:序列是由多个session构成的(以时间为分割的不同密集行为子序列),同一session内的用户行为是相似的(用户通常在同一个session中带有明确且独特的倾向),不同session间的用户行为可能是相异的(不同session中用户的兴趣差异较大),这其实也和DIEN中的“用户兴趣是微观连续,宏观漂移的”的理论是一致的。
作者认为现有的大部分用户序列建模方法忽略了session这个问题,基于此,作者提出了DSIN,即Deep Session Interest Network,用以从session到sequence的视角更细粒度地对用户行为序列建模,达到提升ranking效果更好的目的。
主要创新点:
- 使用加入bias encoding的self-attention(与传统position encoding不同)对session进行encoding,提取session中的用户兴趣。
- 使用Bi-LSTM去建模用户session间的兴趣变化和交互过程。
- 用Activation Unit来学习不同session对候选商品的注意力分数。
模型改进

作者把模型主要部分划分为了两个parts:
-
User Profile 和 Item Profile Embedding part
-
User Behavior Modeling part
-
Session Division Layer
-
Session Interest Extractor Layer
-
Session Interest Interacting Layer
-
Session Interest Acivating Layer
Session Division Layer

主要作用是把sequence分割成多个sessions,DSIN的分割方法是:用户相邻行为的时间间隔大于30min则进行分割。
Session Interest Extractor Layer


Self-attention不包含位置信息,作者额外引入了位置信息编码,这里编码是三种位置信息的总和:
- 交互行为在session中的位置
- session在sequence中的位置
- 交互行为在sequence中的位置
经过Encoder的ith-session是多个向量的集合,作者对其应用了AvgPooling来聚合成一个向量,用来表征ith-session的Embedding。
训练的损失函数:交叉熵
Session Interest Interacting Layer

作者认为用户的session兴趣在sequence中存在一定上下文联系,对时间顺序的session体现的兴趣的动态变化进行建模能够增强每个session对用户兴趣的表达能力。相较于DIEN的AUGRU,DSIN采用了Bi-LSTM,认为其有更好的序列关系学习能力(但是后面实验怎么没有和AUGRU对比)。
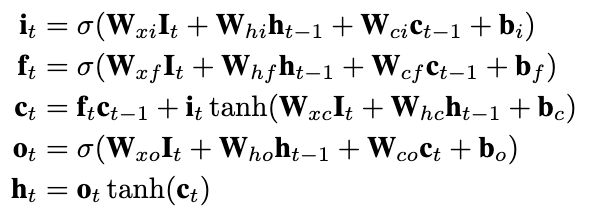

这里的最后一行公式符号应该代表拼接
Session Interest Activating Layer

作者对上述两个层的Session向量分别和候选商品做attention,然后对两个Layer分别进行加权平均,最后和User Profile Embedding以及Item Profile Embedding拼接在一起作为MLP的输入。

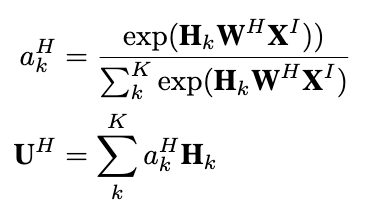
DSIN最后的输出是候选商品的CTR预测值
实验设计
数据集:
- Advertising Dataset:Alibaba的公开数据集
- Recommender Dataset:Alibaba真实私有数据集
Baseline:
- YoutubeNet(without User Behavior)
- YoutubeNet(with User Behavior)
- Wide&Deep
- DIN
- DIN-RNN
- DIEN
评价指标:
- AUC

作者将Baseline与DSIN以及两个变体(bias encoding变为position encoding/去掉session之间的兴趣建模层以及对应的activation unit)进行比较。
注意点
- bias position encoding和传统position encoding不同。
- 作者没有验证Bi-LSTM是否能够比AUGRU or GRU带来更好的效果,我认为这是不足之处。
- 每个session的behavior数是固定的(论文设定为10),多的截断,少的padding,应该就是对变长序列的常见处理方法,而且原文的session是30min间隔,可能普遍场景的交互行为数平均是小于10的。
 公式部分有一个typo
公式部分有一个typo
QA
作者:Ethan Wong
链接:https://zhuanlan.zhihu.com/p/89700141
Q1:在interest extractor层中的mult-head self attention,是根据头将vector平均分为H份吗?如果是,为什么可以均分呢?
A1:不均分。你可以认为每一个head是一个分支,用于提取某一方面的特征。最后回通过ffn提炼出head之间的feature interaction.
Q2:在interest extractor层中的mult-head self attention,如果能做average pooling,I_kQ是一个vector吗?还是说有很多个I_kQ?但是I_k^Q好像已经包含了H个头的信息了。。。
A2:应该是的。我理解I_k^Q是第k个session的特征表示,已经融合了k个head的特征提取结果(FFN的作用)。
Q3:Session Interest Interacting Layer的隐藏层公式里的负号代表相加还是异或?
A3:concatenation
Q4:文章里的公式有好多的W,文章只是说他们是linear matrix,我的理解是待训练的权重,这样想对吗 ?
A4:是的,就是一个projection matrix,都是用来做矩阵乘法的。本质就是一种线性变换。










