基本信息
| 字段 |
内容 |
| 标题 |
Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations |
| 作者 |
Hongyan Tang, Junning Liu, Ming Zhao, Xudong Gong |
| 机构 |
Tencent PCG |
| 年份 |
2020 (RecSys’20 Best Long Paper) |
| 方向 |
Multi-Task Learning, Customized Gate Control (CGC), Progressive Routing, Seesaw Phenomenon |
| 场景 |
腾讯视频多目标推荐排序 |
| 会议 |
https://dl.acm.org/doi/10.1145/3383313.3412236 |
背景/动机/创新点
PLE是在ESMM、MMOE之后提出的一篇多目标任务的论文,在经典的MTL Models上做出改进,号称有效改善了跷跷板问题(跷跷板问题是PLE论文第一个发现的)和负迁移问题,同时在线上视频推荐平台取得了比较大的涨点,这篇文章也获得了RecSys’ 20的最佳长论文奖。
当时已有和PLE类似结构的模型结构,如MMOE、Cross-Stitch Network、Sluice Netwok等,但是这些模型仍旧存在跷跷板和负迁移现象(尽管MMOE已经改善了负迁移的现象)。
PLE为了解决这两个问题提出如下创新点:
- 通过实验发现当时SOTA的模型存在跷跷板现象,即MTL Models对特定任务性能的提升会以牺牲其他任务性能为代价,同时任务性能不会超过单任务目标模型的性能。
- 提出了Progressive Layered Extraction (PLE) model,支持显式的共享Expert和独立Expert,同时采用了progressive routing机制从属于特定任务的共享/独占Expert Component中逐层提取更深层次的寓意信息,能够有效地提升联合表征的能力。
- 线下实验和线上实验证明了PLE的有效性,其中线上AB Test观测到了2.23%view-count提升和1.84%watch-time提升。PLE已经被部署在公司内部应用,并且存在应用在其它推荐领域的潜力。
模型改进
激活函数:ReLU、Softmax
CGC
CGC是PLE的loss简化版+单层Experts版,用于更方便地介绍Customized Gate Control,模型部分的介绍逻辑是:
- 引入CGC结构介绍Gate Control
- 引入PLE结构介绍Progressive Layered Extraction
- 引入样本问题介绍改进后的Loss Function
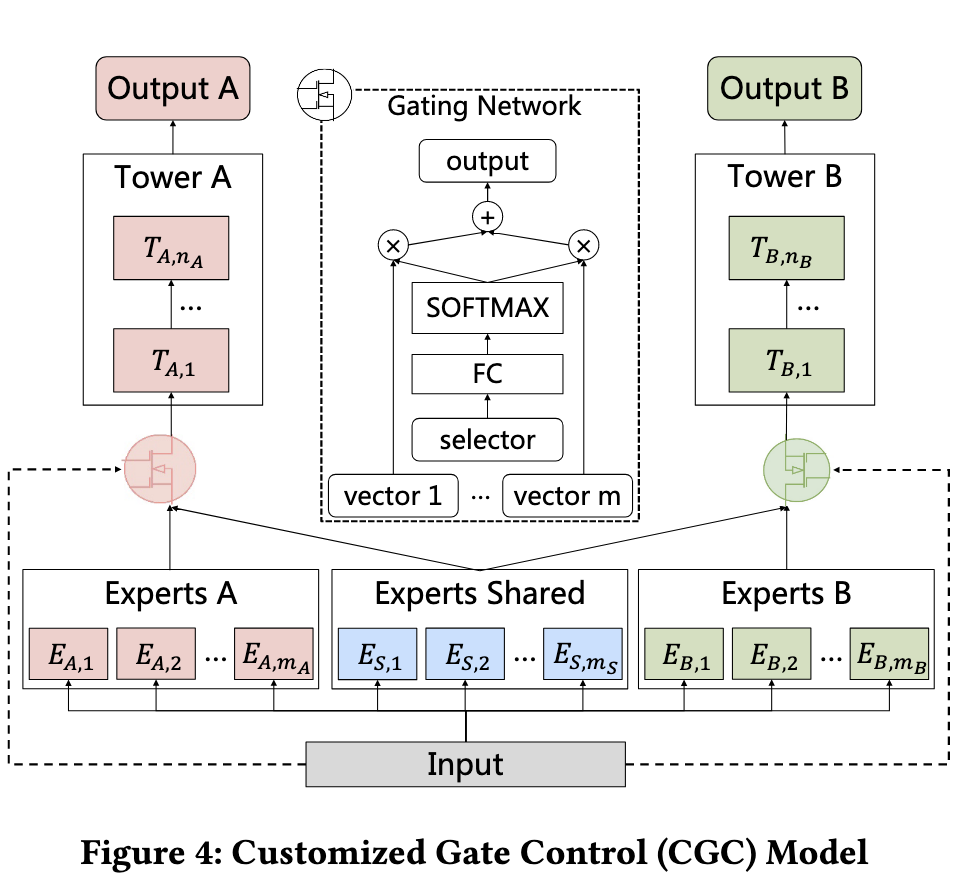
CGC结构是由独占Experts Module A/B、共享Experts Module、Gating Network以及任务之间彼此独立的Tower。其中Expert Module内部又包含多个Experts,如Ea,1、Ea,2等,Experts数量是超参数,tower的width和depth也是超参数。CGC还包含了残差连接。
具体的计算方式如下图所示。

PLE

PLE在CGC的基础上叠加了多层Extraction Network,期望通过逐层提取,将不同任务的参数逐渐分隔开,逐渐提取任务深层信息。

PLE的计算方式和CGC相同,只不过输入是上一层的输出,输出是下一层的输入。
Joint Loss Optimization

作者发现在现实场景的推荐系统中有两个关键的问题:
- 不同的用户行为产生的样本空间也不相同,具体如上图所示,某些任务的某些样本不适用于其它任务。
- MTL模型的性能对loss weight的选择很敏感
作者提出以下两个解决办法:
 修改Loss Function,使得在任务中没出现的样本直接忽略
修改Loss Function,使得在任务中没出现的样本直接忽略 设置超参数,每个epoch结束动态更新loss weight
设置超参数,每个epoch结束动态更新loss weight
实验设计
作者设计了三个实验:
- 面向腾讯视频推荐场景的离线和在线实验(私有数据集)
- 基于公开数据集的实验评估
- Expert利用率研究实验
私有数据集实验
数据集:腾讯视频推荐场景系统采样的8天用户log (2.682 million videos and 0.995 billion samples)
Baseline:CGC、PLE、Single-task model、Asymmetric Sharing、Customized Sharing、Cross-stitch Network、Sluice Network、MMOE、ML-MMOE
目标函数:
- AUC (for VTR 有效观看的概率/CTR 点击概率,这两个训练时损失函数都是交叉熵)
- MSE(for VCR 观看时长比例,这个训练时损失函数是MSE)
- MTL Gain(MTL score - Single Model Score)
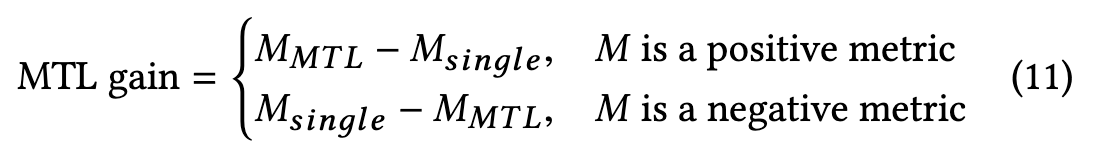
实验设置:
- 7天数据做训练,1天数据做测试
- Tower用3层MLP搭配ReLU实现
- multi-level的MTL Models均采用两层
实验首先验证VTR/VCR的task group,因为这两者之间的关联比较复杂。针对VTR和VCR的实验结果如下,证明了明显的跷跷板现象。

实验接下来验证CTR和VCR的task group,来观察常规关联的任务效果。结果如下:

两个不同task group的实验证明了CGC和PLE对不同task的泛用性。
在线实验针对VTR、VCR、SHR和CMR开展,结果如下:

实验结果证明了PLE在AUC或MSE上小的提升能够在线上带来大幅度的提升。
公开数据集实验
这部分实验是为了验证PLE在非推荐场景的效果
数据集:
- Synthetic Data 合成数据 1.4million samples和2 labels
- Census-income Dataset 299,285samples和40features,同时预测用户收入是否超过50K以及用户是否从未结婚
- Ali-CCP Dataset 84million samples,预测CTR和CVR
实验设置:
- census-income的实验设置参照《Modeling task relationships in multi-task learning with multi-gate mixture-ofexperts》
- Ali-CCP和syntheic data采用3层MLP和ReLU
Baseline:
- Hard Prameter Sharing
- MMOE
- PLE
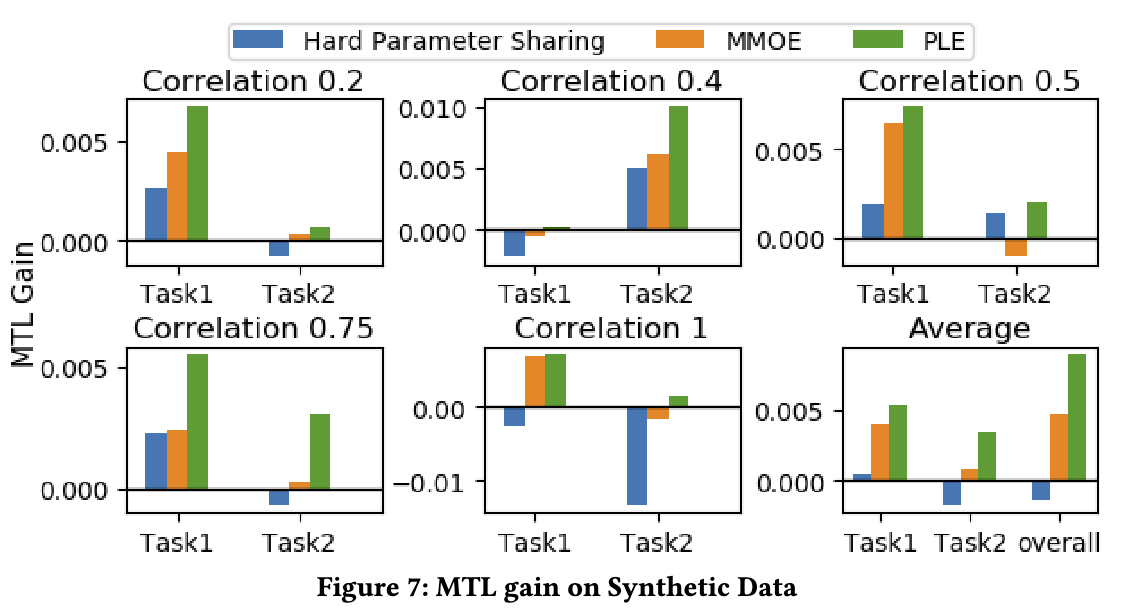
Synthetic Data实验结果如下所示,证明了PLE的稳定性和效果。

Expert利用率研究
数据集选用了VTR/VCR的工业数据集(可能是第一个实验的)。
实验设置:
- CGC和PLE的Expert Module中Expert数量设置为一
- MMOE和ML-MMOE的Experts Module数量设置为3
实验结果如下:

证明了以下三个结论:
- MMOE的结构很难收敛到PLE的结构,因为没有0权重被观察到
- CGC/PLE实现了更好的专家区分度
- 共享专家对提升模型效果有很大帮助
注意点
- 论文提及多层的Extraction Layer能够逐渐分离参数,实验没能证明层数数量更多的时候各层专家的权重变化情况,未能证明分离参数这一点。
- 结构复杂:相比 MMoE,PLE 的网络结构更复杂,参数量通常更大(因为每个任务都要配独享专家)。
- 部署成本:在推理延时敏感的场景下,多层 PLE 可能会带来额外的计算开销。
手撕
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
| import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
"""简单的多层感知机,用于实现 Expert 和 Tower"""
def __init__(self, input_dim, hidden_units, output_dim, activation=nn.ReLU()):
super(MLP, self).__init__()
layers = []
in_dim = input_dim
for unit in hidden_units:
layers.append(nn.Linear(in_dim, unit))
layers.append(activation)
in_dim = unit
layers.append(nn.Linear(in_dim, output_dim))
self.net = nn.Sequential(*layers)
def forward(self, x):
return self.net(x)
class PLE(nn.Module):
def __init__(self,
input_dim,
num_tasks=2,
num_levels=2,
num_shared_experts=1,
num_specific_experts=1,
expert_hidden_units=[64],
tower_hidden_units=[32]):
super(PLE, self).__init__()
self.num_tasks = num_tasks
self.num_levels = num_levels
self.num_shared_experts = num_shared_experts
self.num_specific_experts = num_specific_experts
self.expert_output_dim = expert_hidden_units[-1]
self.levels = nn.ModuleList()
for i in range(num_levels):
level_dict = nn.ModuleDict()
curr_input_dim = input_dim if i == 0 else self.expert_output_dim
level_dict['shared_experts'] = nn.ModuleList([
MLP(curr_input_dim, expert_hidden_units[:-1], self.expert_output_dim)
for _ in range(num_shared_experts)
])
level_dict['specific_experts'] = nn.ModuleList([
nn.ModuleList([
MLP(curr_input_dim, expert_hidden_units[:-1], self.expert_output_dim)
for _ in range(num_specific_experts)
]) for _ in range(num_tasks)
])
task_gate_input_dim = num_specific_experts + num_shared_experts
level_dict['task_gates'] = nn.ModuleList([
nn.Linear(curr_input_dim, task_gate_input_dim, bias=False)
for _ in range(num_tasks)
])
if i < num_levels - 1:
shared_gate_input_dim = num_tasks * num_specific_experts + num_shared_experts
level_dict['shared_gate'] = nn.Linear(curr_input_dim, shared_gate_input_dim, bias=False)
self.levels.append(level_dict)
self.towers = nn.ModuleList([
MLP(self.expert_output_dim, tower_hidden_units, 1)
for _ in range(num_tasks)
])
def cgc_net(self, inputs, level_idx):
"""
CGC 核心逻辑
inputs: 列表,长度为 num_tasks + 1 (最后为共享输入)
"""
level = self.levels[level_idx]
shared_experts_out = [expert(inputs[-1]) for expert in level['shared_experts']]
specific_experts_out = []
for i in range(self.num_tasks):
task_out = [expert(inputs[i]) for expert in level['specific_experts'][i]]
specific_experts_out.append(task_out)
new_inputs = []
for i in range(self.num_tasks):
curr_experts = torch.stack(specific_experts_out[i] + shared_experts_out, dim=1)
gate_score = level['task_gates'][i](inputs[i])
gate_weight = F.softmax(gate_score, dim=1).unsqueeze(1)
task_out = torch.bmm(gate_weight, curr_experts).squeeze(1)
new_inputs.append(task_out)
if 'shared_gate' in level:
all_specific = [exp for task_exps in specific_experts_out for exp in task_exps]
all_experts = torch.stack(all_specific + shared_experts_out, dim=1)
gate_score = level['shared_gate'](inputs[-1])
gate_weight = F.softmax(gate_score, dim=1).unsqueeze(1)
shared_out = torch.bmm(gate_weight, all_experts).squeeze(1)
new_inputs.append(shared_out)
return new_inputs
def forward(self, x):
inputs = [x] * (self.num_tasks + 1)
for i in range(self.num_levels):
inputs = self.cgc_net(inputs, i)
outputs = []
for i in range(self.num_tasks):
out = self.towers[i](inputs[i])
outputs.append(out)
return torch.cat(outputs, dim=1)
|











