
BLaIR: Bridging Language and Items for Retrieval and Recommendation
BLaIR: Bridging Language and Items for Retrieval and Recommendation
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders |
| 作者 | Yupeng Hou, Jiacheng Li, Xiangjun Fu, Zhankui He, An Yan, Xiusi Chen, Julian McAuley |
| 机构 | University of California San Diego |
| 年份 | 2026 (ACL’26) |
| 方向 | Pretrained Item Embedding, Language-Item Alignment, Retrieval & Recommendation |
| 场景 | 推荐系统中用于检索/排序的 item 文本预训练表示 |
| 数据 | Amazon Reviews 2023 |
| arXiv | https://arxiv.org/abs/2403.03952 |
BLaIR是发表自UCSD,BLaIR这篇文章提出了最新的Amazon Review数据集:Amazon Review 2023,BLaIR也是其中的一个创新点,BLaIR是专门为推荐任务做的Pretrained Embedding Model。
背景/动机/创新点
推荐领域中的任务应当能够利用丰富的自然语言语义信息,早期的工作基本将关注点放在了数据集中的“关键词”语义上,并没有充分发挥自然语言语义信息。
LLM的兴起让推荐系统领域看到了应用LLM的前景,然而如何将巨大量级的item信息与现存LLM结合是一个主要难题,现有(2023)的工作主要分为以下两种方式解决:
- 沿用RAG等类似方法,但是其在特定领域的端到端实现泛化性不强。
- 利用Embedding模型将item和自然语言映射到同一个空间,但是目前(2023)没有专门针对推荐任务的Embedding方法,会导致次优性能和泛化问题。
作者认为方法二针对特定推荐任务的实现存在三个难点:
- 训练目标如何定义?
- 数据应当大量收集,且要用比较新的语料库去匹配现有LLM的学习到的知识的“截止日期”
- 数据要合理管理避免污染,要采用公平的评估手段。
为此,作者提出BLaIR Embedding模型,同时发布Amazon Review 2023数据集,在该数据集上训练BLaIR并把训练目标定义为将用户评论与其相应的项目元数据配对。此外,作者通过固定时间戳将数据分为训练集和测试集,避免了数据污染(咋避免的?)
主要创新点:
- 提出BLaIR模型。
- 发布Amazon Review 2023数据集。
- 提出新训练任务:Complex Product Search,使用LLM构建了一个半合成评估集。
- 基于Amazon Review 2023建立新的Benchmark,并在现有方法的基础上验证了BLaIR的效果和泛化性。
模型改进
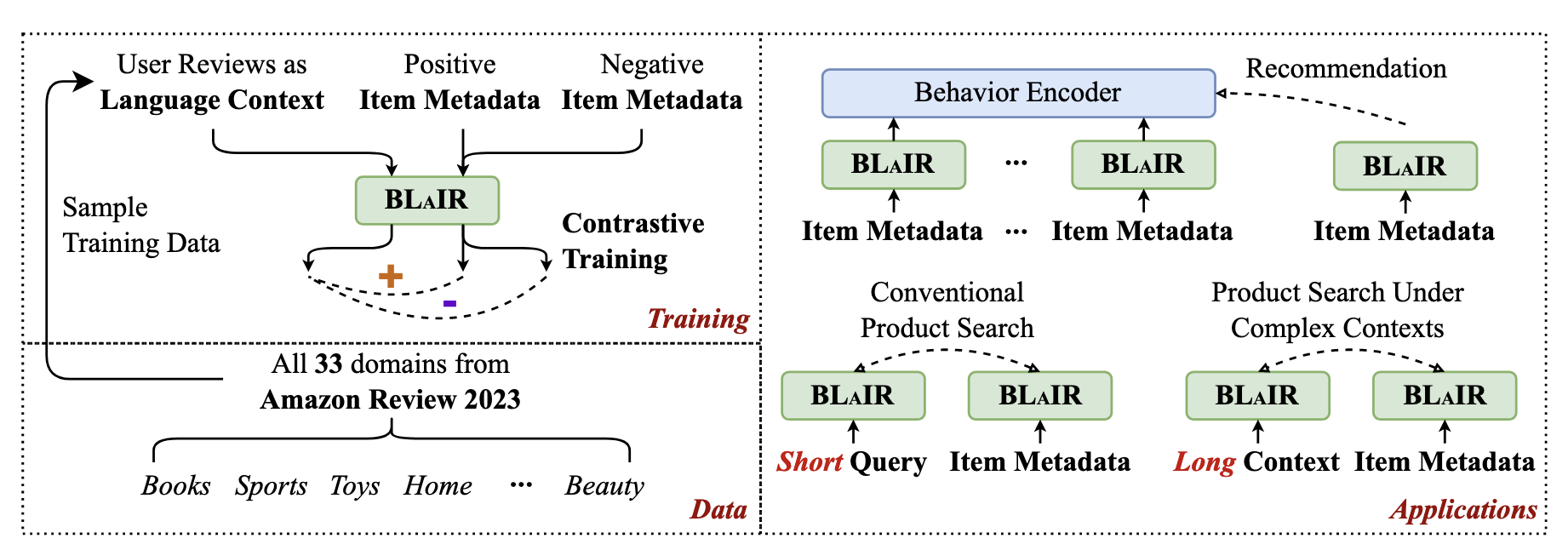
BLaIR并没有原创性设计新的模型架构,它只是基于现有的一些Embedding模型应用新的训练目标和数据集(基于BaseModel参数继续pretrain),因此BLaIR指的应该是一系列的Embedding模型。
训练目标如下图:


Lcl:基于In-batch负采样的Contrastive Loss(Log Softmax)。
Lpt:base模型对应的原有训练目标(BERT/RoBERTa的MLM和T5的DAE)
没了。
实验设计
实验任务:
- 序列推荐任务实验
- conventional product search实验
- complex product search实验
- 泛化性和动态训练分析实验
数据集:Amazon Review 23 固定两个时间戳8:1:1划分train/valid/test
sample格式:两个句子,sentence1=[review_title, review_content],sentence2=[item_title, item_features, item_description]
数据清理

- 过滤少于30字符数的样本
- 对Amazon Review 23 数据集采用10%降采样
序列推荐任务实验

训练任务是给定包含metadata的交互item序列,预测下一个item,这里BLaIR先对每个item data进行embedding再送入序列推荐模型
评估指标:
- NDCG
- Recall
Baseline:
- SASRec
- UniSRec
Conventional Product Search
训练任务是给定用户query(通常包含几个关键词或短段落),预测用户下一个感兴趣的item
数据集:ESCI,也是Amazon平台的数据。
Complex Product Search
数据集:Amazon-C4
样本内容:长、详细且复杂的用户query(通常是多轮对话和复杂的用户指令)
Amazon-C4的数据集是使用ChatGPT基于真实user review构建的(让gpt以用户口吻生成多轮对话)

评估指标:
- Recall
- NDCG
泛化性和动态参数分析实验
想解决的问题:
- multi-domain training效果是否会比in-domain training效果好
- BLaIR采取哪种训练顺序效果会更好(1.对比学习 2.MLP/DAE 先后/后先/同时)
对于第一个问题,这个问题是在探讨:“使用所有品类的数据(多域)来训练 BLAIR,是否会比只用特定品类的数据(单域)训练,效果更好?”
具体来说,论文中的实验是这样做的:
- In-domain training (单域训练): 选定一个下游任务的特定领域,比如 “Games”(游戏)领域。然后,只使用 AMAZON REVIEWS 2023 数据集中 “Games” 这一个品类的数据来训练一个 BLAIR 模型 。
- Multi-domain training (多域训练): 使用 AMAZON REVIEWS 2023 数据集中 所有 33 个品类 的数据来训练一个 BLAIR 模型 。
然后,他们在 “Games” 领域的下游任务(如序列推荐、产品搜索)上比较这两个模型的性能 。
实验的答案是:是的,多域训练表现更好。
论文发现,在所有域上训练的模型(multi-domain)在 “Games” 任务上的表现普遍优于只在 “Games” 域上训练的模型(in-domain)。这表明,在多品类数据上进行预训练能够提高 BLAIR 的泛化能力,即使目标任务的数据分布可能与多域数据有所不同 。
对于第二个问题,在这篇论文中,作者比较了两种不同的训练“课程”:
- 课程 A (直接训练):
- 使用 RoBERTa 初始化模型 。
- 直接在“上下文-物品元数据对”上进行对比学习训练 。
- 课程 B (分阶段训练):
- 使用 RoBERTa 初始化模型 。
- 第 1 步: 先只用“物品元数据”(item metadata)进行 MLM 任务训练(即训练 BLAIR-MLM)。
- 第 2 步: 然后再用“上下文-物品元数据对”进行对比学习训练。
结论:
- multi-domain training效果更好,因为实验证明其有充足泛化性(尽管和数据分布有较大关联)。
- 实验显示直接实验效果更好。










