
DIN: Deep Interest Network
DIN: Deep Interest Network
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | Deep Interest Network for Click-Through Rate Prediction |
| 作者 | Guorui Zhou, Chengru Song, Xiaoqiang Zhu, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, Kun Gai |
| 机构 | Alibaba Group |
| 年份 | 2018 (KDD’18) |
| 方向 | Local Activation Attention, User Behavior Modeling, CTR Prediction, Mini-batch Aware Regularization, Dice |
| 场景 | 电商展示广告 CTR 排序 |
| arXiv | https://arxiv.org/abs/1706.06978 |
概述
DIN模型是由快手团队于2018年提出的CTR预测任务中的一种用户行为序列建模方案,充分揣摩用户行为序列的同时又进行了工程性很强的实验。此外,DIN仅通过一些机制上的朴素改动实现了较好的效果。
作者对用户行为进行了细致的观察,认为传统的将用户行为序列的向量直接AveragePooling成一个向量欠缺考量,因为用户行为序列中的交互物品对候选商品具有不同的影响(相比于衣服相关的交互行为,行为序列中手机相关的交互行为可能对耳机类候选商品被选择的影响更大,或者说更能反应用户的兴趣偏好)。因此应当引入用户行为序列与候选商品的相似性考量,而隔壁NLP当时比较好用的attention机制恰好能满足这一特性,作者基于此实现了ActivationUnit,并根据注意力分数进行SumPolling,得到了更能反应用户对商品兴趣偏好的行为序列向量。
除此之外,作者提出了两个创新点:1.mini-batch aware regularization. 2.Dice ReLU,前者为了减小Embedding表每次更新时的计算量,后者使得激活函数更加平滑,训练效果更好。
实验部分,作者使用GAUC和RelaImpr指标作为目标函数,主要进行了三个实验:1.在MovieLens和Amazon数据集上与baseline比较AUC和RelaImpr,同时对DiceReLU做消融实验。2.在Alibaba数据集(规模小于前两者)上验证mini-batch aware regularization(MBA)的效果,与其他Reg方法进行比较。3.在Alibaba数据集上对DIN做消融实验,同时与baseline model做比较。
实验结果证明了DIN的出色表现和潜力,最后作者对模型进行了线上A/B实验,证明了DIN确实能有较大的效果提升,展现了工业应用的可行性。此外作者还可视化地展示了用户行为序列中不同交互行为对候选商品的注意力大小,证明了attention的设计对于分析用户兴趣是work的。
创新点:
- 利用Attention机制学习用户每个交互行为对候选商品兴趣分数
- 提出MBA正则化,减小L2-Norm计算量
- 提出DiceReLU Dice部分比PReLU更平滑,实验证明效果更好
模型部分

左侧是BaseModel,主要看右侧。右侧的训练流程比较易懂,先对每个交互商品做Embedding,不同特征用不同Embedding表(注意每个Embedding的颜色)。对于单个交互商品的特征向量列表进行拼接,然后做基于注意力分数的SumPooling,然后同用户其他信息、候选商品信息、上下文信息(pid,time)的embdding拼接,喂入MLP。
损失函数使用的Softmax的Negative log-likelihood function,即负对数似然估计。
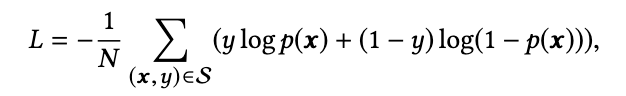
从Softmax出发用极大似然估计推到损失函数时能够得到负对数似然。
Activation Unit

DIN的activation unit中不仅有注意力操作,还要将注意力分数值(在源码实现中是Hadamard乘积)和query以及key还有query-key的值拼接后送入MLP,论文中并未提及减操作,但是DIN源码使用了减法,用于表示向量之间的差异。
Dice ReLU

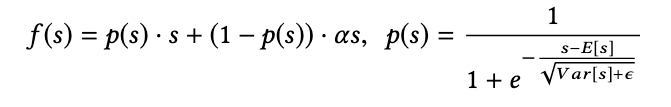
p(s)相当于是对标准化后的s值做sigmoid。

从图像上来看,Dice能带来更平滑的效果,实验验证效果更好些。
Mini-batch Aware Regularization
如果对Emebdding表的权重参数使用L2-norm,会导致每个mini-batch都会将整个表的权重参数计算一遍,开销极大,作者在DIN模型中改成了“对仅出现在每个mini-batch中的稀疏特征对应的embeeding向量进行更新,同时防止特征出现过多导致的过度惩罚”

注意点
- attention计算时并没有归一化,即去掉了softmax层,为了保留用户兴趣的强度
对于不同的候选商品,其对用户序列的激活强度应该不同,“如果候选商品真的不对用户胃口,没有必要非得让行为序列的每个物料评分总和一致”,传统的归一化方法导致计算结果失去了数值上的区分度

- 论文尝试了用LSTM对用户行为序列进行建模,但是效果不好,因为用户行为序列中不同行为并不一定有内在联系,行为序列中可能包含用户多重的兴趣,而且兴趣的跨越时间可能比较长(为后面的DIEN埋下伏笔)
- DIN的注意力操作在源码实现中是外积,且Acitivation Unit中的注意力是[queries, key, queries-key, queries*key]的结果送入MLP,最后得到的一个一维向量。
实验部分
GAUC/RelaImpr指标

就是对不同用户的AUC指标做加权平均,权重一般设置为每个用户view或click的次数。

RelaImpr主要用于直观比较不同model的AUC效果










