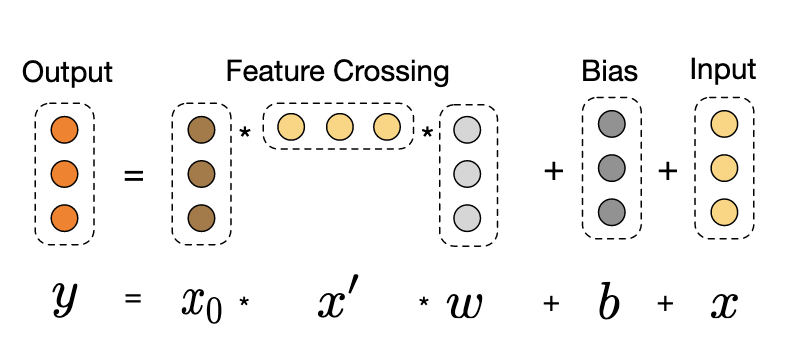
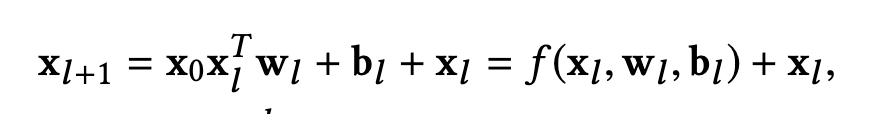1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
| import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossNetwork(nn.Module):
"""
Cross Network 核心层
公式: x_{l+1} = x_0 * (x_l^T * w_l) + b_l + x_l
"""
def __init__(self, input_dim, num_layers):
super(CrossNetwork, self).__init__()
self.num_layers = num_layers
self.kernels = nn.ParameterList(
[nn.Parameter(torch.nn.init.xavier_normal_(torch.empty(input_dim, 1)))
for _ in range(num_layers)]
)
self.biases = nn.ParameterList(
[nn.Parameter(torch.nn.init.zeros_(torch.empty(input_dim, 1)))
for _ in range(num_layers)]
)
def forward(self, x_0):
"""
x_0: 输入张量, shape (batch_size, input_dim)
"""
x_0 = x_0.unsqueeze(2)
x_l = x_0
for i in range(self.num_layers):
xl_w = torch.tensordot(x_l, self.kernels[i], dims=([1], [0]))
dot_ = torch.matmul(x_0, xl_w)
x_l = dot_ + self.biases[i] + x_l
return x_l.squeeze(2)
class DCN(nn.Module):
"""
Deep & Cross Network 完整模型
"""
def __init__(self, feat_sizes, embedding_size,
dense_feature_dim, cross_num_layers=2,
dnn_hidden_units=[128, 64], dnn_dropout=0.0):
"""
feat_sizes: dict, 稀疏特征的 {feature_name: vocabulary_size}
embedding_size: 稀疏特征 Embedding 维度
dense_feature_dim: 稠密特征的维度和
"""
super(DCN, self).__init__()
self.embeddings = nn.ModuleDict({
feat: nn.Embedding(vocab, embedding_size)
for feat, vocab in feat_sizes.items()
})
self.input_dim = len(feat_sizes) * embedding_size + dense_feature_dim
self.cross_net = CrossNetwork(self.input_dim, cross_num_layers)
dnn_layers = []
input_act = self.input_dim
for hidden_unit in dnn_hidden_units:
dnn_layers.append(nn.Linear(input_act, hidden_unit))
dnn_layers.append(nn.ReLU())
dnn_layers.append(nn.Dropout(dnn_dropout))
input_act = hidden_unit
self.dnn = nn.Sequential(*dnn_layers)
final_dim = self.input_dim + dnn_hidden_units[-1]
self.final_linear = nn.Linear(final_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x_sparse, x_dense):
"""
x_sparse: dict, key为特征名, value为 (B, ) 的 LongTensor
x_dense: (B, dense_feature_dim) 的 FloatTensor
"""
sparse_embeds = [self.embeddings[feat](x_sparse[feat]) for feat in x_sparse]
sparse_embeds = torch.cat(sparse_embeds, dim=-1)
x_0 = torch.cat([sparse_embeds, x_dense], dim=-1)
cross_out = self.cross_net(x_0)
deep_out = self.dnn(x_0)
stack_out = torch.cat([cross_out, deep_out], dim=-1)
logits = self.final_linear(stack_out)
return self.sigmoid(logits)
if __name__ == "__main__":
BATCH_SIZE = 8
EMBEDDING_SIZE = 4
DENSE_DIM = 5
FEAT_SIZES = {"feat_user": 100, "feat_item": 50, "feat_category": 20}
dummy_sparse = {
"feat_user": torch.randint(0, 100, (BATCH_SIZE,)),
"feat_item": torch.randint(0, 50, (BATCH_SIZE,)),
"feat_category": torch.randint(0, 20, (BATCH_SIZE,))
}
dummy_dense = torch.randn(BATCH_SIZE, DENSE_DIM)
model = DCN(
feat_sizes=FEAT_SIZES,
embedding_size=EMBEDDING_SIZE,
dense_feature_dim=DENSE_DIM,
cross_num_layers=3,
dnn_hidden_units=[32, 16]
)
print(f"Model Structure:\n{model}")
try:
output = model(dummy_sparse, dummy_dense)
print("\n=== Forward Pass Successful ===")
print(f"Input Dense Shape: {dummy_dense.shape}")
print(f"Combined Input Dim: {len(FEAT_SIZES) * EMBEDDING_SIZE + DENSE_DIM}")
print(f"Output Shape: {output.shape}")
print(f"Prediction Examples: \n{output.detach().view(-1)}")
loss = output.mean()
loss.backward()
print("Backward Pass Successful (Gradient Computed).")
except Exception as e:
print(f"Error: {e}")
|