
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
xDeepFM
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems |
| 作者 | Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, Guangzhong Sun |
| 机构 | University of Science and Technology of China; Microsoft Research Asia |
| 年份 | 2018 (KDD’18) |
| 方向 | Compressed Interaction Network, Vector-wise Feature Crossing, DNN + CIN |
| 场景 | CTR 预估中的向量级显式特征交叉 |
| arXiv | https://arxiv.org/abs/1803.05170 |
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
extreme Deep Factorization Machine
从名字上看是从DeepFM延伸过来的,但其实最大的改进是基于DCN做的。xDeepFM整体架构上采用了类似Wide&Deep的方案,不过Wide侧替换为了作者提出的CIN架构,CIN架构是在改进DCN的基础上得来的,作者在论文中证明了DCN的一些问题。
动机/背景/创新
作者认为传统特征工程有三个问题:
- 高质量特征需要有比较高的代价(时间/人力)
- 大规模的预测系统产生大量特征数据,人工提取难度很大
- 人工交叉的特征没有泛化性
作者认为传统FM存在以下问题:
- FM会去对所有特征进行交叉,可能会导致一些无用的组合,引入噪音导致模型退化。
作者认为DNN存在以下问题:
- DNN模型对高阶特征进行隐式建模,没有理论依据,无法界定其交互到多少阶合适
- DNN模型的特征交互式bit-wise level的,即是基于拼接好的每个元素的,没有Filed Feature的概念,传统FM是vector-wise的
作者在文章中重点强调了显式建模和隐式建模,认为不能只有隐式建模。
创新点:
- 提出了xDeepFM,能够同时显式和隐式地对特征进行交叉建模
- 提出CIN网络,用于显式地且vector-wise地学习高阶特征
- 实验证明SOTA
模型改进
DCN问题分析
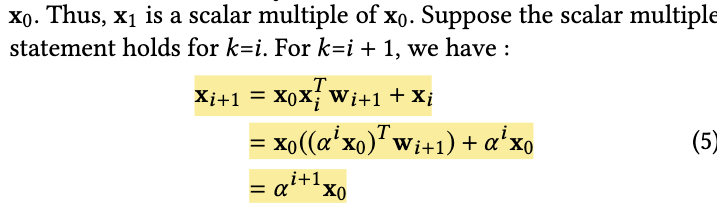
作者认为DCN的显式高阶特征交叉虽然有不错的效率,但是会将高阶特征限制在一个特殊的形式,即原始输入的倍数(这不代表输出和输入存在线性关系,但是输出的形式确实被限制住了)。此外DCN特征交互是bit-wise的,作者认为不如vetcor-wise,从直觉上理解也确实如此。
CIN模型
Compressed Interaction Network

作者认为提出的CIN模型有三个优势:
- 显式高阶特征交叉
- vector-wise建模方式
- 计算复杂度不会随交互阶数呈指数增长
CIN中间层有好几层X矩阵,每个矩阵宽度为vector数量,长度为embedding维度,每层X中的vector都会SumPooling成标量输出,并拼接在一起作为完整输出,从输入输出和训练流程角度来看有点像RNN。
X的计算方式如下,第k层的每个vector和第0层的每个vector分别做Hadamard乘积,最后加权求和得到一个D维向量作为Xk的第h层向量:

其特征交叉的方式有点像CNN。

每层X都会对vector沿着dimmension进行SumPooling,类似于FM计算内积。

最后使用Sigmoid得到最后输出。
为了简便,作者将每层X的H数设定为相同大小。
由此可见,CIN之所以叫压缩感知层,是因为CIN在计算过程中每次矩阵W都会将两两交互的特征压缩成一维。
CIN复杂度分析
空间复杂度:

直接上论文,作者称如果必要的话,W可以做矩阵分解,但是实际上CIN的复杂度与dimmension维度无关。
如果使用矩阵分解,则复杂度变为
时间复杂度:
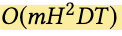
多项式估计
这块没看,后面慢慢补上。
整体架构
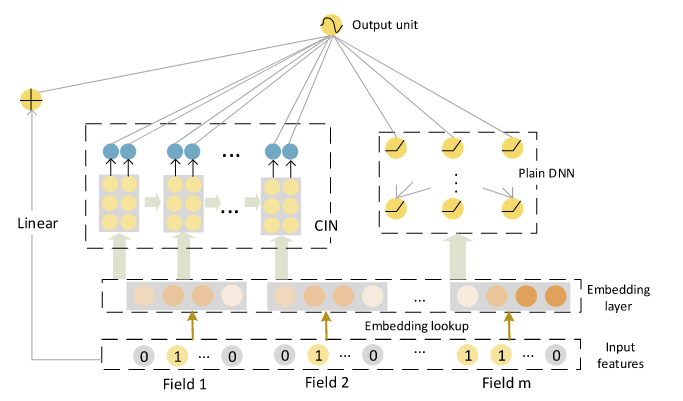
Wide+Deep
最后的预测值计算方式如下:

其中a是原始特征(未经过Embedding),激活函数:Sigmoid
损失函数 log loss+L2-Norm:


作者认为设定CIN层数为1且feature map向量为1时,CIN其实就是DeepFM中FM层的推广,其中FM层的每个特征交叉都学习了不同的权重。去掉DNN部分,使用SumPooling的feature map就等同于传统的FM模型
实验设计
数据集:
- Criteo Dataset:CTR预测任务的工业数据集
- DianPing Dataset: 大众点评数据集
- Bing News Dataset
评估指标:
- AUC 用于评估排序准确性
- LogLoss 用于评估预测值准确性(作者认为比较类似评估排序收益)
Baseline:
- LR
- FM
- DNN
- PNN (better one from iPNN/oPNN)
- Wide&Deep
- DCN
- DeepFM
作者认为实验的目的是验证特征交互的效果,所以作者并没有添加人工交叉特征
实验方案:
- 针对CIN/CrossNet/FM/DNN四个模块的效果比较
- 针对不同模块组合(Baseline)的模型效果比较
- 不同超参数设置的模型效果探讨
未来工作
- 研究分布式版本的xDeepFM方案,因为xDeepFM复杂度过高
- 研究对包含多值的特征更好的聚合方案(现有方案是SumPooling),可能会参考DIN的Attention做法
注意点
- 作者在实验部分并为对模型训练效率开展实验,结尾部分也提及模型复杂度太高,需要优化










