
Wide&Deep
Wide & Deep Learning for Recommender Systems
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | Wide & Deep Learning for Recommender Systems |
| 作者 | Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, Rohan Anil, Zakaria Haque, Lichan Hong, Vihan Jain, Xiaobing Liu, Hemal Shah |
| 机构 | |
| 年份 | 2016 (DLRS’16 @ RecSys’16) |
| 方向 | Memorization-Generalization Tradeoff, Wide+Deep Joint Training, Feature Crossing |
| 场景 | Google Play 应用商店 app 推荐 CTR 预估 |
| arXiv | https://arxiv.org/abs/1606.07792 |
2016年Google提出的一篇同时进行低阶特征交叉和高阶特征交叉的文章,全文简短精炼,只有4页。
DeepFM在随后一年被提出
动机/背景/创新点
- 作者提出推荐系统需要关注两个性能:memorization(记忆性)和generalization(泛化性),前者主要是挖掘用户历史交互商品的特征联系,后者是推测历史从未出现的新的特征的结合的交互强度。
- 常用的cross-product的特征交叉方法无法泛化出没有出现过的特征对
- 基于Embedding的模型可能会导致过度泛化:当“用户-物品”交互矩阵是“稀疏且高秩”**时,**这意味着1:大部分用户只与极少部分物品有交互。2.物品受众非常狭窄,绝大数用户和物品之间没有联系。Embedding模型在处理稀疏且高秩的场景时会导致过度泛化,通俗来讲,它无法很好地处理“例外规则”或“小众偏好”。
基于LR模型和Embedding模型的各自弊端,作者提出将两者结合,同时解决泛化性和记忆性问题,LR为Wide侧,Embedding为Deep侧,前者做低阶特征交叉,后者做高阶特征交叉。
创新点:
- 提出低阶和高阶特征同时交叉的Wide&Deep架构
模型改动


模型设计比较通俗易懂,Wide侧不做Embedding直接做LR,Deep侧做Embedding后直接喂入MLP,最后结果和Wide侧相加。
整体训练目标:
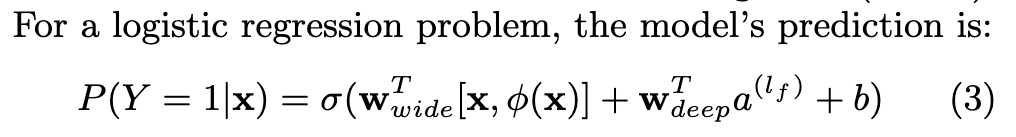
其中的最后激活函数是Sigmoid,两侧的输出值通过Wwide和Wdeep加权求和
损失函数Log Loss:

Wide侧

输入为:1.原始特征 2.人工设计的交叉特征
交叉特征例如“ ”
”
Wide侧的优化器为带有L1正则化的FTRL优化器
Deep侧

没啥好说的,先做Emedding,然后喂进MLP
激活函数:ReLU
Deep侧的优化器为AdaGrad
实验设计
数据集: Google Play产生的数据集
评估指标:
- 线下AUC
- 线上Acuisition Gain(下载率?)
实验设计:
- A/B实验,每个实验组随机抽1%用户
- 系统时延实验
注意点
- Wide侧和Deep侧用的优化器不一样。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Baisen's Blog!
相关推荐










