
word2vec
word2vec: Efficient Estimation of Word Representations in Vector Space
基本信息
| 字段 | 内容 |
|---|---|
| 标题 | Efficient Estimation of Word Representations in Vector Space |
| 作者 | Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean |
| 机构 | |
| 年份 | 2013 (ICLR Workshop’13) |
| 方向 | Word Embedding, Skip-gram, CBOW, Negative Sampling |
| 场景 | NLP 词向量预训练;推荐系统中作为 item embedding 训练范式借鉴 |
| arXiv | https://arxiv.org/abs/1301.3781 |
论文解读参考: word2vec Parameter Learning Explained (Xin Rong)
动机/背景/创新点
在当时,NLP大部分向量化的word都是被表示为对应word的序号Indice,这通常是出于简便、鲁棒性,以及当时的观点:训练在大规模数据的简单模型比训练在小规模数据的复杂模型效果好,N-gram就是最流行的做法。
作者认为这种方法有很多局限性:
- 很多领域(语音识别、小语种等)的高质量数据集有限,无法支撑起大规模N-gram训练
当时背景:
- 算力开始支撑地起训练更复杂的模型基于更大的数据
- NN-based语言模型在效果上显著好于N-gram的模型
创新点:
- 设计了一个模型架构,能够更好地保留单词间的线性规律,单词之间不只能体现相似性,还能体现不同程度的相似性,同时利用当时的训练框架,能够实现万亿级别的单词训练。
- 设计了一个深入实验去验证新模型语法和语义的相似性
- 讨论了不同维度和不同大小的训练数据是如何影响训练时间与准确度的
模型复杂度分析
作者先分别介绍了当时NNLM和RNNLM的复杂度,这里先挖个坑,后期有空再补上。


模型改进
作者基于以下观察来对模型进行改进:
- 模型大部分的复杂性是由非线性隐藏层导致的,作者尝试寻找简单模型,这虽然不能像NN一样表征得很准确,但是能够训练数据更高效
- 模型训练可以分为两阶段:1.使用普通模型学习单词表征。2.使用N-gran NNLM基于这些单词表征进行训练。
作者提出两种获取单词连续表征得模型:1.Continuous Bag-of-Words Model 2.Continuous Skip-gram Model。
两个模型的损失函数是Log Softmax。
Continuous Bag-of-Words Model (CBOW)

将所有输入(History and Future)聚合到同一个位置,即基于上下文预测中心词。原始论文并没有详细解释是具体是如何预测的,以下是Xin Rong大佬(RIP)对Word2Vec的CBOW的详细解释:
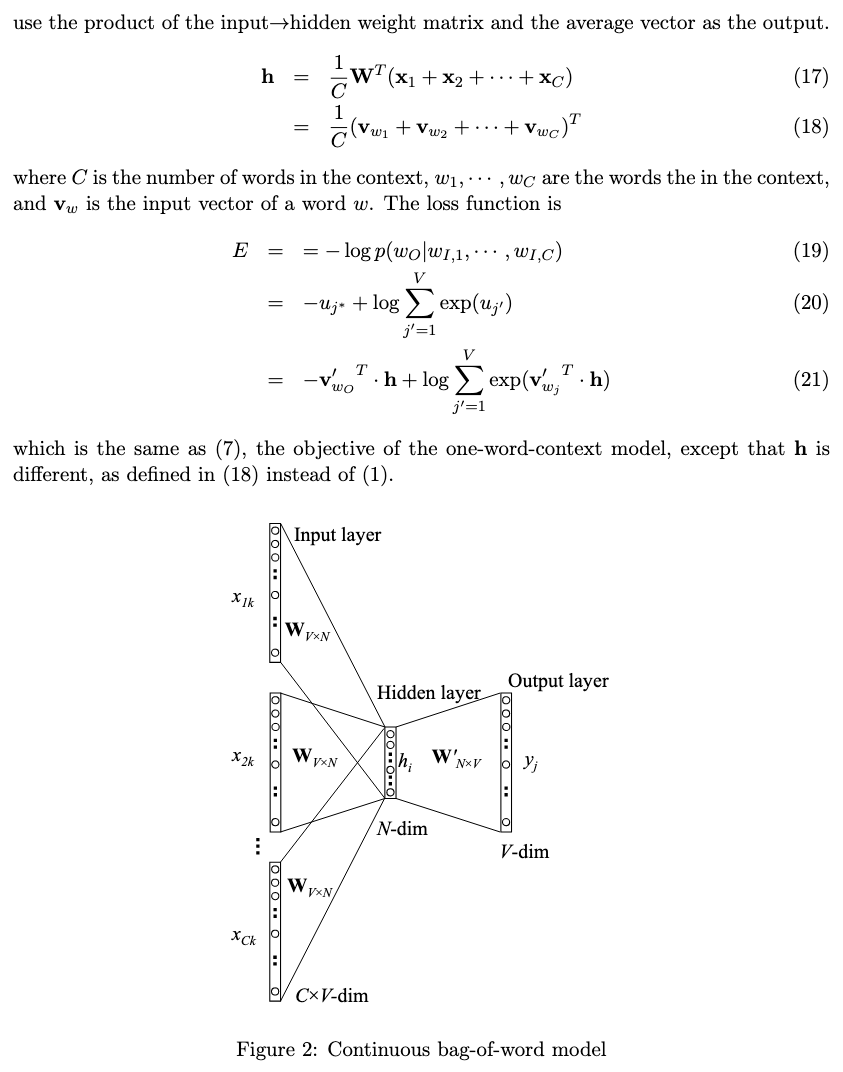
梯度更新部分我没细看,后面有时间再来填坑。
上下文信息聚合是通过上下文word的Embedding做AvgPooling得到的,然后得到的h向量对中心词向量做Softmax的点积计算,其中分母范围是整个词表的词向量,注意h向量是与从W’权重矩阵计算出来的中心词向量做点积,而不是W。
训练复杂度:

Continuous Skip-gram Model

使用中心词预测窗口内上下文单词。
原始论文并没有介绍具体是如何预测的,参考的Xin Rong大佬的详细解释:


做法和CBOW类似,只不过是用中心词向量和其它上下文词向量分别做Softmax点积,这里的上下问向量是由W’计算出来的,而不是W。
无论是CBOW还是Skip-gram,其训练目标并没有学习单词和上下文之间的位置关系,而只是在固定“信息窗口”中为目标词向量聚合信息,进而学习潜在的语法语义关系。
训练复杂度:

Hierarchical Softmax
Hierarchical Softmax和Negative Sampling都是为了解决在训练过程中计算量大的问题,这会导致无法扩大训练的词表规模,二者都是对output vector做的更新优化。

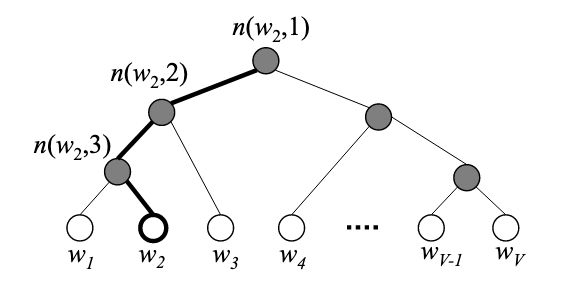
Hierarchical Softmax用二叉树来表征词向量,在二叉树中,所有的词向量都作为叶子结点存在,每个词向量都有一条unique的路径从根节点到叶子结点。
在Hierarchical Softmax中,叶子结点没有output vector,每个非叶子结点都有一个output vector,某个单词成为最终输出的单词的概率被表示为:


ch为n(w,j)的左子叶,即左子叶wo路径要走左侧的话输出1,否则输出-1,最后整个word向量的计算结果变成了:

不难发现每个叶子结点的概率和是1,因为激活函数是sigmoid,对于一个父节点的input vector和output vector内积值v’h,其大小应该等同于其左叶子结点和右叶子结点的值的和。
梯度计算的计算过程省略了,后面有时间再写:
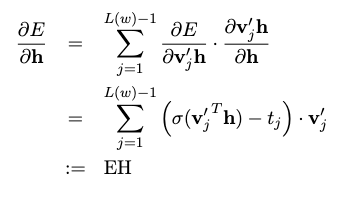
Hierarchical Softmax 通过将Softmax转变成了多层的Sigmoid,将**“词表中选中目标单词的概率”这一行为展开为“哈夫曼树中最终叶子结点是目标单词的概率”**,进而降低了计算复杂度。
至于哈夫曼树是如何以单词频率为权重建立的,可以参考:数据结构——哈夫曼树(Huffman Tree) - 川上流觞的文章 - 知乎https://zhuanlan.zhihu.com/p/415467000
Negative Sampling
负采样的思想更加直接:**为了softmax防止大量output vector被更新导致的大量计算,我们只采样其中一部分。**作者认为基于负采样的word2vec的大体计算方式是如下形式:


梯度计算推导部分同样留给后续工作。
结果分析
作者发现可以利用单词向量之间的线性相似性直接通过线性计算去得到某个单词。
比如X = vector(“biggest”)-vector(“big”)+vector(“small”)
model(X) = vector(“smallest”)
实验设计
作者设计了多种语法和语义问题来检验单词向量的质量,如下表:

数据集:Google News
实验设计:
- 不同Dimmension和词数量对准确度的影响
- 不同模型之间语义/语法准确度比较
- 不同模型在不同Dimmension下的准确度和训练时间差异
实验发现:1. Skip-gram模型效果好于CBOW,但是训练时间更长,直观上来看因为1-n prediction的训练难度更大
注意点
- CBOW和Skip-gram模型均有两个权重矩阵,一般前者被视为词向量矩阵,后者用来反映单词的搭配状况,也有做法是将两个权重矩阵取平均,计算得到最后的词向量矩阵。设置两个权重矩阵可能是因为梯度计算更加简洁。
常见问题
摘选自:
1、word2vec中目标函数为什么不用加正则化项?
加正则的本质是减少数据中的误差对模型的影响。word2vec中输入数据是one hot encoding没有误差所以不用加。
2、Word2vec的基础性假设。
具有相同上下文的中心词具有可替换性
3、Word2Vec哪个矩阵是词向量?
无论是CBOW还是Skip-Gram中,都有两个权重矩阵W和W‘,W 反映的是一个词本身的词义,W’ 反映的是其他词与该词的搭配状况。上下文词向量的意思不是上下文单词的词向量,而是用来反映单词搭配状况(而非这个词的词义本身)的向量。一般来说词向量是指 W(因为用到下游任务的时候,W’ 的功能被 RNN 或其他网络结构代替了)。也有文章把 W 叫 input embedding,把 W’ 叫 output embedding。
4、word2vec使用词向量平均值表示整段文本,这种方法可靠吗?
这种做法就是bag of words模型。对于短文本是OK的。也可以考虑增加词权重,常用的无监督权重idf,有监督的权重chi2或者pmi。
5、word2Vec的CBOW,SKIP-gram为什么有2组词向量?
训练两组词向量是为了计算梯度的时候求导更方便。如果只用一组词向量 ,那么Softmax计算的概率公式里分母会出现一项平方项 ,那么再对 求导就会比较麻烦。相反如果用两套词向量,求导结果就会很干净。实际上,因为在窗口移动的时候,先前窗口的中心词会变成当前窗口的上下文词,先前窗口的某一个上下文词会变成当前窗口的中心词。所以这两组词向量用来训练的词对其实很相近,训练结果也会很相近。一般做法是取两组向量的平均值作为最后的词向量。
6、为什么使用word2vec得出的词向量,可以用向量的距离来衡量词相似度? 因为:
如果设它们都是单位向量,则
这与word2vec的训练目标是一致的。
并且word2vec是有前提假设的,它假设了“具有相同上下文的中心词具有可替换性”,这与word2vec的两种训练模式cbow和skip-gram这是完全吻合的。
7、word2vec如何处理语料中的高频词和低频词的。
高频
在论文中介绍,一些常出现的词往往意义不是很大,如“的”、“是”等词,那么我们可以采用一种叫做亚采样的方式(sub sampling)去解决这样的问题,从而来提高训练速度。具体的做法如下:给定一个词频阈值参数t,词w将以

低频
利用语料C建立词典D时,并不是每个出现过的词都能收录到词典中.代码中引入一个叫做min_count的阀值参数(默认取值为5), 若某个词在语料中出现的次数小于它,则将其从词典中刪除.如果不想做任何删除,则只需将min_count取为0或1即可.注意,这些未能进入词典D的词在训练时也是不可见的.可以简单地理解为训练前语料进行了这样一次预处理:将所有出现次数小于min_count的词都去除掉.
8、Negative Sampling是如何进行负采样的?
word2vec采样的方法并不复杂,如果词汇表的大小为V,那么我们就将一段长度为1的线段分成V份,每份对应词汇表中的一个词。当然每个词对应的线段长度是不一样的,高频词对应的线段长,低频词对应的线段短。每个词w的线段长度由下式决定:

采样前,我们将这段长度为1的线段划分成M等份,这里M>>V,这样可以保证每个词对应的线段都会划分成对应的小块。而M份中的每一份都会落在某一个词对应的线段上。在采样的时候,我们只需要从M个位置中采样出neg个位置就行,此时采样到的每一个位置对应到的线段所属的词就是我们的负例词。
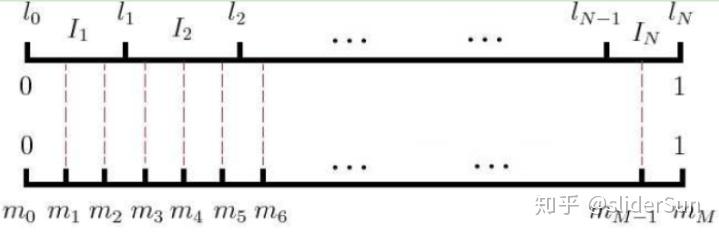
在word2vec中,M取值默认为 。
9、Hierarchical Softmax的缺点?
遇到生僻词的时候,在哈夫曼树中也要走很久,计算量也很大。
hierarchical softmax对生僻词很不友好,因为词频越高的词在离根节点越近的叶子节点,词频越低的词在离根节点越远的叶子节点,也就是说当该模型在训练到生僻词时,需要走很深的路径经过更多的节点到达该生僻词的叶子节点位置,训练的时间更长。而负例采样在对生僻词进行训练时,训练时要找的反例词个数不变,所以每次训练更新的参数的个数不变,花费的训练时间不变,这样就会让训练速度更稳定,不会因为生僻词而使训练耗费更多的时间
也有人认为这个结论不对:
“hierarchical softmax对生僻词很不友好”这个结论需要修改,理由是:
- 如果这句话是想表达 “hierarchical softmax得到的生僻词Embedding效果不好”,这个结论并不能从 “对生僻词的训练时间更长” 来得出;况且从实验证据来看h-softmax对于生僻词的训练效果相比负采样要更好[1,2]{[1,2]}[1,2]。另外注意,这个现象尚且没有理论解释,StackExchange上有帖子在讨论原因,但目前没有令人信服的结论[3]{[3]}[3]
- 如果这句话只是想表达“对生僻词的训练时间更长”,这是对的但是却没必要提,并且更不能总结成“hierarchical softmax对生僻词很不友好”这种不够明确的结论。哈夫曼编码与哈夫曼树对于结点访问效率的提升是整体的效果,生僻词需要经过更多结点换来的是常用词经过更少的结点,从而换来整体的访问效率(在W2V背景下对应着训练效率)的提升,这是哈夫曼树的精髓而不是缺点,所以说这是对的但是却没必要提.
10、CBOW和skip-gram相较而言,彼此相对适合哪些场景。
CBOW比Skip-gram 训练速度快,但是应用场景基本一样,不过实践角度而言,skip-gram训练出来的词向量会稍好一点,因为模型的训练机制会对向量的预测能力要求更高(1 predict n)。
11、Word2Vec中为什么使用负采样?
12、Word2vec模型究竟是如何获得词向量的?
Word2vec是不涉及到隐层的,CBOW有投影层,只是简单的求和平均,Skip-gram没有投影层,就是中心词接了一个霍夫曼树。对每个词都初始化了一个词向量作为输入,这个词向量是会随着模型训练而更新的,词向量的维度就是我们想要的维度,比如说100维。以Skip-gram为例,我们的输入的中心词的词向量是随机初始化的一个词向量,它会随着模型训练而更新。
13、为什么要做层次softmax?
从隐藏层到输出的softmax层的计算量很大,因为要计算所有词的softmax概率,再去找概率最大的值,其计算复杂度为 ,VVV是词表总长度,而从数据结构角度来思考,一般查找的问题可以优化到 ,因此论文设计了层次softmax来近似模拟softmax计算,将计算复杂度降至
14、hierarchical softmax的哈弗曼树怎么构造的?叶子结点,根结点,非叶子结点都代表了什么?
hierarchical softmax的哈弗曼树是根据单词在语料库中的词频来构造的,哈夫曼树的构造过程与数据结构中哈夫曼树的构造过程一致。假设词表中有n个单词,则构造出来的哈夫曼树有n个叶子结点,假设这n个单词的词频分别为w1,w2,…,wnw_1,w_2,…,w_nw1,w2,…,wn。
将w1,w2,…,wnw_1,w_2,…,w_nw1,w2,…,wn当做 棵树(每棵树1个结点)组成的森林。
选择根结点权值最小的两棵树,合并,获得一棵新树,且新树的根结点权值为其左、右子树根结点权值之和。词频大的结点作为左孩子结点,词频小的作为右孩子结点。
从森林中删除被选中的树,保留新树。
重复2、3步,直至森林中只剩下一棵树为止。
叶子结点代表词表中的每一个单词,根结点代表投影后的词向量,即隐藏层输出的向量,非叶子结点代表从根结点到某个单词路径上的中间结点,在数据结构中的含义是其所有子树对应结点之和。
15、哈夫曼树二分类,左右子树怎么分的,为什么左为负1,右为正0,能不能换?
关于Huffman树和Hufman编码,有两个约定:
(1) 将权值大的结点作为左孩子结点,权值小的作为右孩子结点;
(2) 左孩子结点编码为1, 右孩子结点编码为0。
在word2vec源码中将权值较大的孩子结点编码为1,较小的孩子结点编码为0。
这个只是一个约定,方便之后计算概率,也可以约定左边为0,右边为1,推导过程都是类似的。
(1)Word2Vec两个算法模型的原理是什么,网络结构怎么画?
(2)网络输入输出是什么?隐藏层的激活函数是什么?输出层的激活函数是什么?
(3)目标函数/损失函数是什么?
(4)Word2Vec如何获取词向量?
(5)推导一下Word2Vec参数如何更新?
(6)Word2Vec的两个模型哪个效果好哪个速度快?为什么?
(7)Word2Vec加速训练的方法有哪些?
(8)介绍下Negative Sampling,对词频低的和词频高的单词有什么影响?为什么?
(9)Word2Vec和隐狄利克雷模型(LDA)有什么区别与联系?
以上问题可以通过本文和参考文章找到答案,这里不再详细解答。
(10)介绍下Hierarchical Softmax的计算过程,怎么把 Huffman 放到网络中的?参数是如何更新的?对词频低的和词频高的单词有什么影响?为什么?
Hierarchical Softmax利用了Huffman树依据词频建树,词频大的节点离根节点较近,词频低的节点离根节点较远,距离远参数数量就多,在训练的过程中,低频词的路径上的参数能够得到更多的训练,所以效果会更好。
(11)Word2Vec有哪些参数,有没有什么调参的建议?
Skip-Gram 的速度比CBOW慢一点,小数据集中对低频次的效果更好;
Sub-Sampling Frequent Words可以同时提高算法的速度和精度,Sample 建议取值为
;
Hierarchical Softmax对低词频的更友好;
Negative Sampling对高词频更友好;
向量维度一般越高越好,但也不绝对;
Window Size,Skip-Gram一般10左右,CBOW一般为5左右。
(12)Word2Vec有哪些局限性?
Word2Vec作为一个简单易用的算法,其也包含了很多局限性:
Word2Vec只考虑到上下文信息,而忽略的全局信息;
Word2Vec只考虑了上下文的共现性,而忽略的了彼此之间的顺序性;










